It is easy to parse S-Expressions in C# with OMeta. Our code limits the grammar to lists, and atoms of string, symbol, and number types. So, it is not complete, but it can easily be expanded with OMeta. What motivated me to write this article was the lack of publicly available S-Expression parsers in C#/.NET.
Our parser converts the expression (+ (* 3 4 5 6) (- 7 1) ) to the following tree:
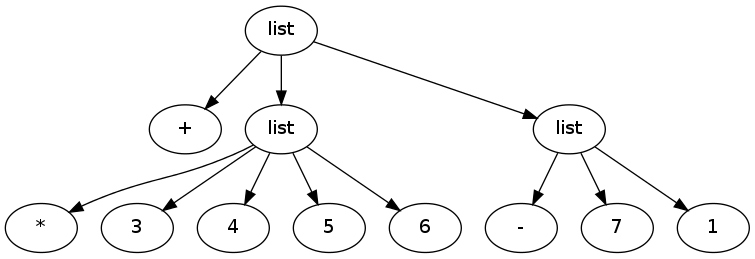
where each vertex is represented by a C# class containing an ArrayList, Symbol, String, or Integer. Note that the expression (1) is different from the expression without parenthesis. The first is a list with one atom and the other is just the atom.
S-Expressions are a compact way to express programs and data structures. They were first defined for Lisp, but are used in a variety of areas including public key infrastructure. We use S-Expressions to define data flows in Egont, our web orchestration language. In Egont, each S-Expression produces a tree which is converted into a directed acyclic graph, the subject of a future post.
OMeta can be used under C# via the OMeta# project. That makes it more interesting since the classical lexical analyzer and parser generators such as Lex/flex and Yacc/GNU bison do not produce C# code. ANTLR is an interesting alternative but at the time of this post the latest version, ANTLR 4, does not support C#. OMeta’s ability to deal with ambiguities makes it more suited to playing with grammars. However, there are performance penalties in OMeta which must be taken into account.
Code
The code is available as SExpression.NET [github.com].
- Compile the RebuildParser project first
- Run the Test project
- The SExpression project contains the SExpression.ometacs parser and its related C# classes
See Also
Additional Resources
- IronMeta: another OMeta implementation in C#
- YaYAML: a YAML parser written in OMeta#
- OMeta Performance
