This is a guest post by Hartley Brody, whose book “The Ultimate Guide to Web Scraping” goes into much more detail on web scraping best practices. You can follow him on Twitter, it’ll make his day! Thanks for contributing Hartley!
Hacker News is a treasure trove of information on the hacker zeitgeist. There are all sorts of cool things you could do with the information once you pull it, but first you need to scrape a copy for yourself.
Hacker News is actually a bit tricky to scrape since the site’s markup isn’t all that semantic — meaning the HTML elements and attributes don’t do a great job of explaining the content they contain. Everything on the HN homepage is in two tables, and there aren’t that many classes or ids to help us hone in on the particular HTML elements that hold stories. Instead, we’ll have to rely more on patterns and counting on elements as we go.
Pull up the web inspector in Chrome and try zooming up and down the DOM tree. You’ll see that the markup is pretty basic. There’s an outer table that’s basically just used to keep things centered (85% of the screen width) and then an inner table that holds the stories.
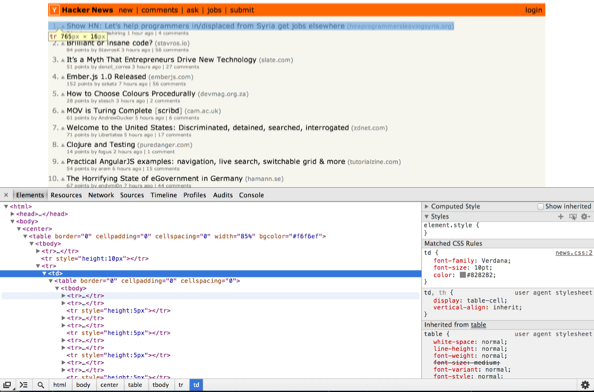
If you look inside the inner table, you’ll see that the rows come in groups of three: the first row in each group contains the headlines and story links, the second row contains the metadata about each story — like who posted it and how many points it has — and the third row is empty and adds a bit of padding between stories. This should be enough information for us to get started, so let’s dive into the code.
I’m going to try and avoid the religious tech wars and just say that I’m using Python and my trusty standby libraries — requests and BeautifulSoup — although there are many other great options out there. Feel free to use your HTTP requests library and HTML parsing library of choice.
In its purest form, web scraping is two simple steps: 1. Make a request to a website that generates HTML, and 2. Pull the content you want out of the HTML that’s returned.
As the programmer, all you need to do is a bit of pattern recognition to find the URLs to request and the DOM elements to parse, and then you can let your libraries do the heavy lifting. Our code will just glue the two functions together to pull out just what we need.
import requests
from BeautifulSoup import BeautifulSoup
# make a single request to the homepage
r = requests.get("https://news.ycombinator.com/")
# convert the plaintext HTML markup into a DOM-like structure that we can search
soup = BeautifulSoup(r.text)
# parse through the outer and inner tables, then find the rows
outer_table = soup.find("table")
inner_table = outer_table.findAll("table")[1]
rows = inner_table.findAll("tr")
stories = []
# create an empty list for holding stories
rows_per_story = 3
# helps us iterate over the table
for row_num in range(0, len(rows)-rows_per_story, rows_per_story):
# grab the 1st & 2nd rows and create an array of their cells
story_pieces = rows[row_num].findAll("td")
meta_pieces = rows[row_num + 1].findAll("td")
# create our story dictionary
story = { "current_position": story_pieces[0].string, "link": story_pieces[2].find("a")["href"], "title": story_pieces[2].find("a").string, }
try:
story["posted_by"] = meta_pieces[1].findAll("a")[0].string
except IndexError:
continue # this is a job posting, not a story stories.append(story)
import json
print json.dumps(stories, indent=1)
You’ll notice that inside the for loop, when we’re iterating over the rows in the table two at a time, we’re parsing out the individual pieces of content (link, title, etc) by skipping to a particular number in the list of <td> elements returned. Generally, you want to avoid using magic numbers in your code, but without more semantic markup, this is what we’re left to work with.
This obviously makes the scraping code brittle, if the site is ever redesigned or the elements on the page move around at all, this code will no longer work as designed. But I’m guessing from the consistently minimalistic, retro look that HN isn’t getting a facelift any time soon. ;)
Extension Ideas
Running this script top-to-bottom will print out a list of all the current stories on HN. But if you really want to do something interesting, you’ll probably want to grab snapshots of the homepage and the newest page fairly regularly. Maybe even every minute.
There are a number of cool projects that have already built cool extensions and visualizations from (I presume) scraping data from Hacker News, such as:
- http://hnrankings.info/
- http://api.ihackernews.com/
- https://www.hnsearch.com/
It’d be a good idea to set this up using crontab on your web server. Run crontab -e to pull up a vim editor and edit your machine’s cron jobs, and add a line that looks like this:
* * * * * python /path/to/hn_scraper.py
Then save it and exit (<esc> + “:wq”) and you should be good to go. Obviously, printing things to the command line doesn’t do you much good from a cron job, so you’ll probably want to change the script to write each snapshot of stories into your database of choice for later retrieval.
Basic Web Scraping Etiquette
If you’re going to be scraping any site regularly, it’s important to be a good web scraping citizen so that your script doesn’t ruin the experience for the rest of us… aw who are we kidding, you’ll definitely get blocked before your script causes any noticeable site degradation for other users on Hacker News. But still, it’s good to keep these things in mind whenever you’re making frequent scrapes on the same site.
Your HTTP Requests library probably lets you set headers like User Agent and Accept-Encoding. You should set your user agent to something that identifies you and provides some contact information in case any site admins want to get in touch.
You also want to ensure you’re asking for the gzipped version of the site, so that you’re not hogging bandwidth with uncompressed page requests. Use the Accept-Encoding request header to tell the server your client can accept gzipped responses. The Python requests library automagically unzips those gzipped responses for you.
You might want to modify line 4 above to look more like this:
headers = { "User-Agent": "HN Scraper / Contact me: ", "Accept-Encoding": "gzip", }
r = requests.get("https://news.ycombinator.com/", headers=headers)
Note that if you were doing the scraping with some sort of headless browser or something like Selenium which actually downloads all the resources on the page and renders them, you’d also want to make sure you’re caching the stylesheet and images to avoid unnecessary extra requests.
If you liked this article, you might also like:
- Scraping Web Sites which Dynamically Load Data
- Ideas and Execution Magic Chart (includes a Hacker News Search Hack)
- Running Your Own Anonymous Rotating Proxies





